Creating a Repository for Retention
The data is saved in a repository for a defined retention period. Each VPG has Retention sets created according to a schedule. The Retention sets are fixed points saved either daily, weekly, monthly, or yearly in the repository, with a pre-defined expiration date.
Before you begin
Before you can start a Retention process for VPGs, you must first create one or more repositories that will be used as a target for the Retention sets.
The Repository can be an empty share or a non-empty repository with existing content. When a non-empty repository is connected to the ZVM, all its valid Retention sets will be synced and become available for Restore. Only successfully completed Retention processes result in valid Retentions sets.
After the Repository has been created, it can be selected as a target in the VPG retention policy configuration.
A Repository can be defined with an IP, DNS or hostname.
As long as there is at least one Repository defined on the Recovery site, Extended Journal Copy can be enabled.
Before creating a Repository, review the following:
| • | The minimum supported network speed between the VRA and the Extended Journal Copy repository is 10MB/s. |
| • | Minimum CPU requirements when using Extended Journal Copy are 2 vCPUs per Recovery VRA. |
| • | See the Interoperability Matrix for All Zerto Versions. |
| • | See Supported Storage Types. |
| • | See Repository Prerequisites |
After reviewing the required information, proceed to Creating a Repository.
Supported Storage Types
As the Retention process runs on the recovery site, the Repositories are connected to the recovery ZVMs. The following storage and connection types are supported:
| Storage Category | Storage Type | Connection Type | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Cloud Storage |
Amazon S3 | S3 | ||||||||||||
|
S3-Compatible Storage Note: Zerto does not test and validate all S3-compatible storage platforms and services that can be potentially utilized by end-users. Therefore, it is the end-user responsibility to validate the S3 API version and to ensure that it meets the required list of S3 API actions/calls utilized by Zerto. For more information about S3-compatible storage, see Using S3-Compatible Storage as a Repository Type for Extended Journal Copy. |
S3 | |||||||||||||
| Microsoft Azure Storage | Azure API | |||||||||||||
| Google Cloud | S3 | |||||||||||||
|
Network Attached Storage |
Network Share |
NFS |
||||||||||||
|
SMB |
||||||||||||||
|
Purpose-built Backup Appliances (PBBAs) (non-selectable title) |
|
NFS |
||||||||||||
|
SMB
|
||||||||||||||
| HPE StoreOnce | HPE StoreOnce Catalyst |
Repository Prerequisites
| • | Amazon S3 |
| • | An AWS Identity and Access Management (IAM) user must be predefined with a role that has sufficient privileges to perform the following API actions on the desired S3 bucket to be used as a Zerto Extended Journal Repository: |
| • | CompleteMultipartUpload (in Zerto 9.0 and later) |
| • | CreateMultipartUpload (in Zerto 9.0 and later) |
| • | DeleteBucketPolicy |
| • | DeleteObject |
| • | DeleteObjectVersion |
| • | GetObject |
| • | GetObjectAcl |
| • | GetObjectVersion |
| • | GetBucketObjectLockConfiguration |
| • | ListBucket |
| • | ListBucketVersions |
| • | ListObjectVersions |
| • | PutObject |
| • | PutObjectAcl |
| • | PutObjectRetention |
| • | RestoreObject (from 9.0 for AWS) |
| • | UploadPart (in Zerto 9.0 and later for AWS S3 and Zerto 9.0 Update 3 for S3-Compatible) |
| • | HTTPS access is allowed from all VRAs and ZVM in the Recovery site vs. AWS cloud storage. |
| • | The S3 bucket exists. |
A single Repository is defined on top of a single bucket, which is assumed to be used exclusively by Zerto.
| • | Encryption-at-rest is supported and must be enabled and managed by the customer. |
| • | Predefined AWS Identity and Access Management (IAM) user with sufficient permissions to manage the S3 bucket . |
| • | VRAs in the Recovery site are configured with DNS setting. |
| • | Starting from Zerto version 9.0, data is written to AWS S3 Repositories using Multipart Upload. |
| • | To support immutability on this Repository, enable S3 Versioning and S3 Object Lock on the S3 bucket before creating the Repository. For more information see, Immutability. |
| • | To support tiering for the Repository, no lifecycle management policies must be defined on the S3 bucket, as tiering is based on Zerto's own algorithms. For more information, see Tiering. |
| • | S3-Compatible Storage |
| • | The S3-Compatible Repository can be defined on top of an S3 bucket. The S3 bucket can be defined in either on-premise S3-compatible storage or in-cloud. |
| • | A signed certificate is required to be able to properly connect to the Repository. |
| • | Allow HTTPS access from all VRAs and ZVM in the Recovery site vs. the S3-Compatible Storage. |
| • | The following S3 API calls must be supported: |
| • | PutObject |
| • | GetObject |
| • | CopyObject |
| • | DeleteObject |
| • | HeadObject |
| • | ListObjectsV2 |
| • | HeadBucket |
| • | Data is written to S3-Compatible Repositories using Multipart Upload. |
| • | Microsoft Azure |
| • | Before creating a new Repository based on Microsoft Azure Storage, you need a predefined Azure Application with a single predefined GPV2 Storage Account. |
For guidelines, see this Knowledge Base article.
| • | A single Repository is associated with a single Storage Account, which is assumed to be exclusively used by Zerto. |
| • | The Azure Service Principal must be defined with “Storage Blob Data Owner” role and “Storage Account Contributor” in the SA scope. |
| • | Allow HTTPS access from all VRAs and ZVM in the Recovery site vs. Azure cloud storage. |
| • | VRAs in the Recovery site are configured with DNS setting. |
| • | The following Azure Clouds are supported: |
| • | Global |
| • | Government |
| • | Starting from Zerto version 9.0, data is written to Azure Repositories using Multipart Upload. |
| • | To support immutability on this Repository, enable Versioning before creating the Repository. For more information see, Immutability. |
| • | To support tiering for the Repository, no lifecycle management policies must be defined on the container, as tiering is based on Zerto's own algorithms. For more information, see Tiering. |
| • | HPE StoreOnce Catalyst |
| • | The Catalyst Store on the HPE StoreOnce appliance must support LBW as the “Transfer policy”. Catalyst API server version should be v9 and above. |
| • | The Catalyst Store on the HPE StoreOnce appliance must allow access to the recovery VRA. The default setting is No Access. A user with Administrator Role can enable access through the Catalyst User Interface. |
| • | The Catalyst Store on the HPE StoreOnce appliance must have credentials already defined. These credential are used when setting up the Repository in the Zerto User Interface. |
| • | The HPE StoreOnce Catalyst repository requires increasing the VRAs RAM to 4GB. 1GB will be allocated for Catalyst usage. |
| • | The Catalyst Store on the HPE StoreOnce appliance must have "Logical Storage Quota" defined. |
The Data Streaming Service (DSS) entity performs all the data copy operations. During the Retention process, the DSS communicates with the VRA on the recovery site.
Creating a Repository
To create a Repository for Extended Journal Copy
| 1. | In the Zerto User Interface, click SETUP > REPOSITORIES > NEW REPOSITORY. |
The New Repository window is displayed.
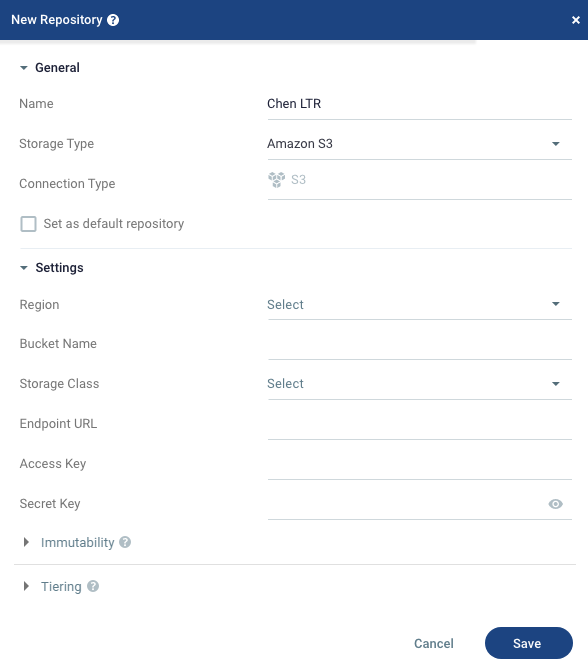
| 2. | Configure as follows: |
| • | In the General area, enter a unique Name for the Repository. |
| • | For each storage category, choose the Storage Type, Connection Type if available, and enter the required settings for each storage type. |
Cloud Storage
| Storage Type | Connection Type | Settings | Mandatory | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Amazon S3 | S3 |
Region: Drop-down of the available AWS regions where the S3 bucket was created. |
Optional if using Endpoint URL | |||||||
| Endpoint URL: The URL of the entry point for an AWS web service. Define the Endpoint URL if a non-default URL is to be used. If the Endpoint URL is left blank, Zerto will use the default Region Endpoint URL. |
Mandatory field when using Region: Other. | |||||||||
| Bucket Name: Name of S3 bucket to be used as the Extended Journal Repository. A single Repository is defined on top of a single bucket. |
P |
|||||||||
| Access Key: IAM user access key to authenticate the S3 request along with the Secret Key provided. |
P |
|||||||||
| Secret Key: IAM user secret key to authenticate the S3 request, along with the Access Key provided. |
P |
|||||||||
|
Storage Class: Drop-down of supported object storage classes that can be used for Extended Journal data on Amazon S3:
The storage classes differ in pricing and availability. |
P |
|||||||||
| Immutability:When enabled, Full Retention sets on the Repository will not be eligible for deletion nor modification until expiry per Retention policy, or for a user-defined period. By default, Immutability is disabled. For more information, see Immutability. |
O |
|||||||||
| Tiering: Zerto allows you to move Retention sets to a lower-cost online and/or offline storage tier as they age out of the restoration window. By default, Tiering is enabled. For more information, see Tiering. |
O |
|||||||||
|
S3-Compatible Storage For more information, see Using S3-Compatible Storage as a Repository Type for Extended Journal Copy Using S3-Compatible Storage as a Repository Type for Extended Journal Copy |
S3 | Region: Drop-down of the available AWS regions where the S3 bucket was created. | Optional if using Endpoint URL | |||||||
| Endpoint URL:The URL of the entry point for the S3-compatible web service. |
P |
|||||||||
| Bucket Name: Name of S3-compatible bucket to be used as the Extended Journal Repository. A Repository is defined on top of a single bucket. |
P |
|||||||||
| Access Key: IAM user access key to authenticate the S3 request along with the Secret Key provided. |
P |
|||||||||
| Secret Key: IAM user secret key to authenticate the S3 request, along with the Access Key provided. |
P |
|||||||||
| Microsoft Azure Storage | Azure API |
Azure Cloud: Select from the available global network of Microsoft-managed datacenters - either Global (default) or Government. |
P |
|||||||
|
Storage Account Name: Azure Storage account name defined for Extended Journal Copy use, associated with the dedicated Azure application. A single Repository is associated with a single Storage Account. |
P |
|||||||||
|
Application ID: Application ID that is registered for Zerto Extended Journal Copy use, which is authorized to access the relevant resources in Azure. For initial setup guidelines, see this Knowledge Base article. |
P |
|||||||||
|
Tenant ID: Azure Tenant ID. For guidelines, see this Knowledge Base article. |
P |
|||||||||
|
Application Key: The client secret key generated for the application in use, which you can typically view only upon creation/setup of the Azure application. For guidelines, see this Knowledge Base article. |
P |
|||||||||
| Tiering: Zerto allows you to move Retention sets to a lower-cost online and/or offline storage tier as they age out of the restoration window. By default, Tiering is enabled. For more information, see Tiering. |
O |
|||||||||
| Google Cloud Storage | S3 | Endpoint URL: The URL of the entry point. | ||||||||
| Bucket Name: Name of S3-compatible bucket to be used as the Extended Journal Repository. A Repository is defined on top of a single bucket. | ||||||||||
| Access Key: IAM user access key to authenticate the S3 request along with the Secret Key provided. | ||||||||||
| Secret Key: IAM user secret key to authenticate the S3 request, along with the Access Key provided. |
Network Attached Storage
| Storage Type | Connection Type | Settings | Mandatory | |||||
|---|---|---|---|---|---|---|---|---|
| Network Share |
NFS |
The network share is connected on top of NFS protocol. Path: This is the path where the Repository will reside. Zerto recommends using an empty folder when creating a new Repository. Format: <IP or DNS name>:/<path> The path must be accessible from the VRA, so if the Repository is on a different domain, the domain must be included in the path. |
P |
|||||
|
SMB |
The network share is connected on top of SMB (CIFS) protocol. Username: The username can be entered using either of the following formats:
|
P |
||||||
| Password: Password to access the network share. |
P |
|||||||
|
Path: This is the path where the Repository will reside. Zerto recommends using an empty folder when creating a new Repository. Format: \\<IP or DNS name>\<path> The path must be accessible from the VRA, so if the Repository is on a different domain, the domain must be included in the path. |
P |
Purpose-built Backup Appliances
| Storage Type | Connection Type | Settings | Mandatory | ||||||
|---|---|---|---|---|---|---|---|---|---|
| DELL EMC Data Domain, ExaGrid, HPE StoreOnce,Other De-Duplicated Storage Appliance |
NFS |
The Purpose-build Backup Appliance is connected on top of NFS protocol. Path: This is the path where the Repository will reside. Zerto recommends using an empty folder when creating a new Repository. The path must be accessible from the VRA, so if the Repository is on a different domain, the domain must be included in the path.
|
P |
||||||
|
SMB
|
The Purpose-build Backup Appliance is connected on top of SMB (CIFS) protocol. Username and password must be provided to access the share. Username: The username can be entered using either of the following formats:
|
P |
|||||||
| Password: Password to access the network share. |
P |
||||||||
|
Path: This is the path where the Repository will reside. Zerto recommends using an empty folder when creating a new Repository. The path must be accessible from the VRA, so if the Repository is on a different domain, the domain must be included in the path. |
P |
||||||||
| HPE StoreOnce |
HPE StoreOnce Catalyst
|
Username: The username can be entered using either of the following formats:
|
P |
||||||
| Password: Password to access the Catalyst store |
P |
||||||||
| Catalyst Server: IP of the HPE StoreOnce appliance that holds the Catalyst store. |
P |
||||||||
| Catalyst Store Name: The Catalyst store name in HPE StoreOnce appliance. |
P |
| 3. | In the Properties area, select the Set as default repository to use the Repository as the default when defining the Retention policy in a VPG. |
| 4. | Click SAVE. The repository is created. |
| 5. | Repeat this procedure to define an additional Repository. Once the repository is created, you can edit or delete it. |
To define an additional Repository, repeat this procedure.
| 6. | When using Zerto Cloud Manager, you must also add the Repository to either the vCenter resources or vCD resources in the Zerto Cloud Manager. For details, see the Creating a Repository for Retention. |
| 7. | Proceed with Enabling Extended Journal Copy for the VPGs. |